ESP32-P4 Smart Vision Terminal
A school embedded-systems competition project. Current version v1.3-tools. Repo at github.com/Hooper18/esp32p4_competition.
What it does
A dual-MCU interactive terminal built around a DNESP32P4 board (ESP32-P4 main chip) and an ESP32-C3 coprocessor. The P4 handles local vision, display, touch, audio, and HUD; the C3 isolates the entire network stack and runs Wi-Fi + HTTPS. The two are linked over UART1 (115200 8N1), carrying every byte of the voice loop, vision queries, and tool calls.
What it looks like
The 5.5″ 720×1280 MIPI LCD displays camera preview with an RGB565 HUD overlay. Stable state:
FPS 30.0 AI 1MS
CAM OK TOUCH OK
C3 OK WIFI OK
RSSI -52 IP 192.168.x.x
NET OK HTTP 204 320MS
mic LVL 3 SPEECH
ASR 7.5s · LLM 5.5s · TTS 5.1s
[REC] [CAM] [STOP]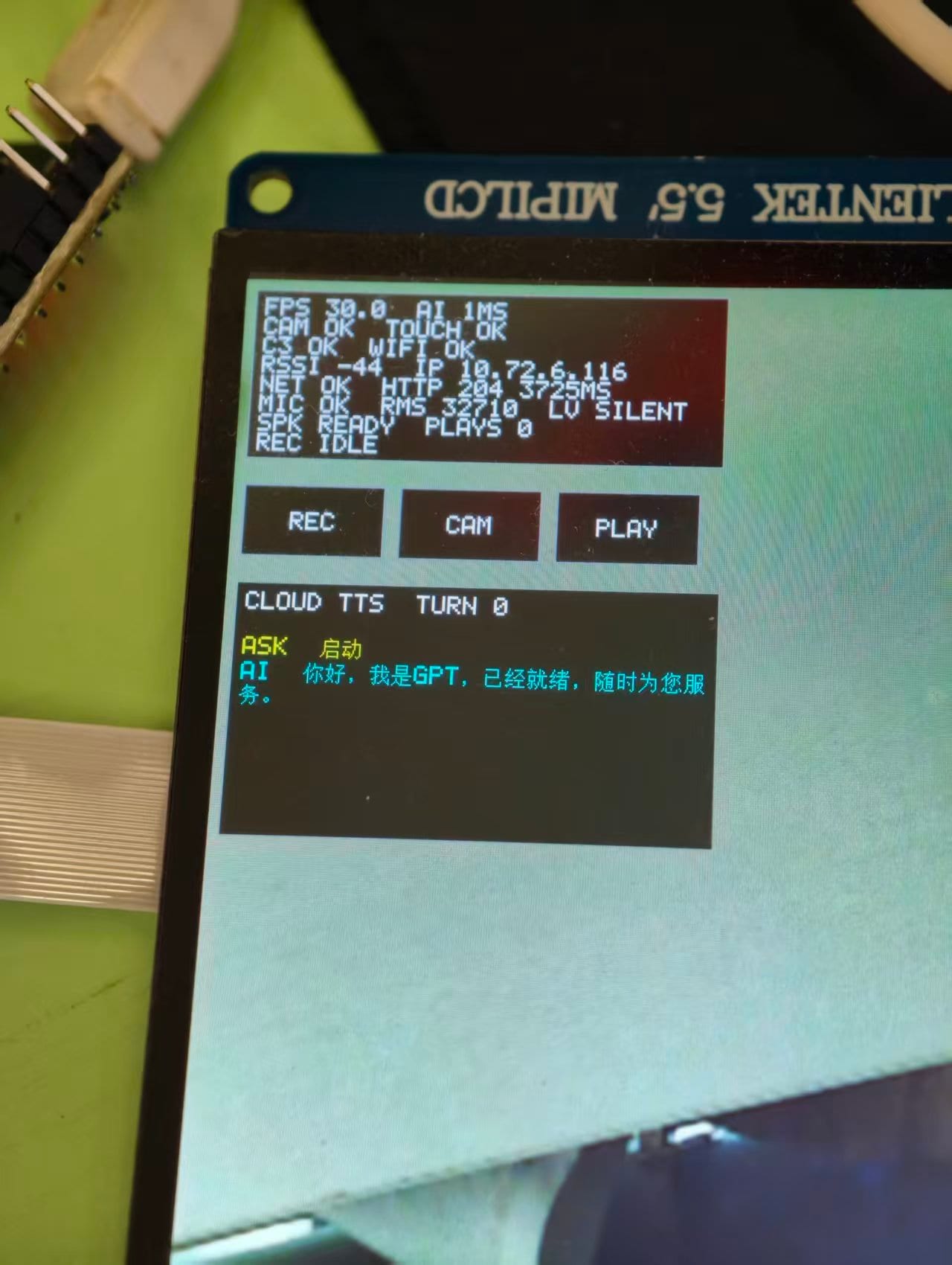
Sample exchanges:
- Ask “what time is it in Beijing” → the speaker answers “14:32 Beijing time”
- Say “beep in 5 seconds” → TTS finishes “sure, timer set,” and 5 seconds later three beeps fire
- Say “take a look and describe it” → GPT calls
take_photoon its own, the frame goes up, GPT answers
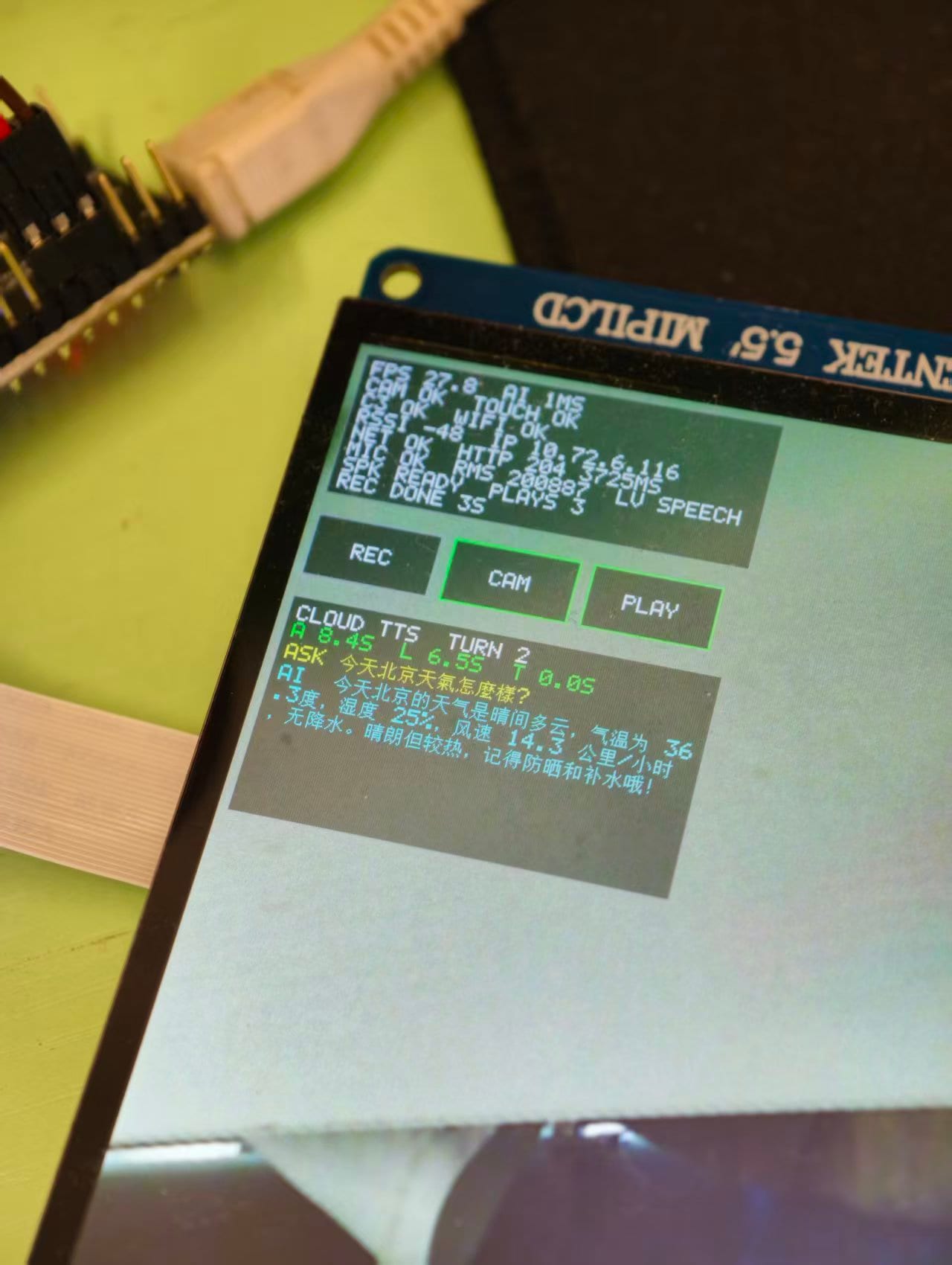

End-to-end latency: ~30 s without tool calls, ~40 s with.
What’s in the box
Hardware
- Main chip: ALIENTEK DNESP32P4 (ESP32-P4 RISC-V 400 MHz + PSRAM + MIPI display/camera hardware acceleration)
- Coprocessor: ESP32-C3-DevKitM-1-N4X
- Display: 5.5″ MIPI DSI LCD 720×1280
- Touch: GT911 over I²C
- Camera: OV5645 MIPI CSI, 1280×960 RGB565
- Mic: INMP441 digital I²S
- Amp: MAX98357A digital I²S
- Interconnect: P4 ↔ C3 UART1, GPIO28/29 ↔ GPIO5/4, started at 115200 baud, later pushed to 460800
Software stack: ESP-IDF v5.5.4 / C/C++ / FreeRTOS / LVGL v9 + esp_lvgl_port / minimp3 / cJSON / PPA framebuffer hardware acceleration / esp_jpeg_enc / OpenAI Whisper · GPT-4o · TTS / Open-Meteo Weather.
Why two MCUs: the ESP32-P4 is powerful but ships with no Wi-Fi/BT radio, so the C3 isolates the full network stack. That lets the P4 stay focused on real-time audio/video (30 fps preview + full-duplex I²S + LVGL UI + AI scheduling) without being interrupted by network work; the C3 absorbs TLS handshakes, cert validation, and HTTP up/down, so the P4 only sees a clean base64 byte stream. The cost: a dual-MCU protocol has to be designed by hand — that turned out to be the project’s single biggest technical challenge.

Features delivered
Inputs
- Voice recording: tap REC to start, again to stop; or let the local VAD auto-stop after 1.5 s of silence
- Image capture: tap CAM to grab a frame; or hold REC + CAM together for “talk while showing”
- Touch: full-screen GT911 + three virtual buttons in the HUD (REC / CAM / PLAY)
Cloud pipeline
- VAD upload trim: typical 5 s recording shrinks 30-50%
- ASR: OpenAI Whisper-1
- LLM: OpenAI gpt-4o-2024-11-20, with a persona system prompt + last 3 turns of history + current Beijing time + function calling
- TTS: OpenAI gpt-4o-mini-tts,
coralvoice, streamed MP3. Digits / ℃ / % are text-preprocessed before synthesis
Function-calling toolset (7)
Local:
get_ambient_sound_level— current ambient loudness bucketget_device_status— Wi-Fi RSSI / uptime / free heaptake_photo— trigger a captureplay_beep(freq, duration)— beep
Network:
get_time— current Beijing time (synced via NTP on the C3)set_timer(seconds)— one-shot timer, fires after TTS playback finishesget_weather(lat, lon)— Open-Meteo weather at any coordinate
Multi-round loop, capped at 3 rounds; the final round drops the tools spec so GPT is forced to wrap up with text.
Outputs
- Streaming TTS playback over I²S (download + decode + play in parallel)
- MIPI DSI 720×1280 LCD: camera preview + RGB565 HUD overlay
HUD live state: C3 link, Wi-Fi, HTTP, mic RMS, speaker status, recording progress, current cloud-pipeline state, per-stage timing, a 5-line scrolling transcript area, and button colors that follow state (green = tappable / grey = busy / red = recording / cyan = playing).

What broke, and how it was fixed
UART link stability
Started with a naive text protocol: one base64 line per frame, HTTP_POST_DATA <b64>\n. A single bit flip aborts the whole frame.
The baud climb: 115200 was too slow (~100 s round trip) → pushed to 230400 / 460800 / 921600, all produced occasional bit flips → fell back to 115200, trading speed for stability. The cause: DuPont wires with no shielding, no hardware flow control — anything above 115200 produces occasional bit flips.
The fix was a v2 protocol: every frame carries seq=NN crc=XXXX (CRC16-LE via the ROM’s esp_rom_crc16_le), stop-and-wait waiting for an ACK before sending the next frame, NAK/timeout triggering retransmission of the same seq up to three times.
v1.0 of the protocol deadlocked on first deploy: camera glitch + buttons frozen. Diagnosis: a 200 ms ACK timeout was nowhere near enough for the upload path — when the C3 calls esp_http_client_write it can block >1 s under TCP backpressure, and the delayed ACK then poisons the next HEALTH heartbeat. v1.2 patched two things: bumped ACK timeout to 2000 ms to cover worst-case backpressure; after retries are exhausted, uart_flush_input clears stale ACKs to cut off the poison path.
Result: 0% uplink CRC errors, 1.3% downlink (every NAK-retransmit succeeded), zero link deadlocks, ASR time 14 s → 7.5 s.
Streaming TTS playback
OpenAI TTS returns an MP3 stream; the goal is download + decode + play in parallel. Feeding minimp3 directly from UART chunks failed: minimp3’s layer-III bit reservoir needs byte continuity across frames, and UART chunk boundaries broke that — 153 consecutive skips after the first frame. Full-buffer-then-decode works but waits >10 s before any sound.
The final design: two tasks + adaptive pre-buffer. The UART chunk callback only appends bytes to a PSRAM accumulator. An independent decoder task pulls from the accumulator into minimp3 → pushes PCM into the audio_service stream ring → a player task drains to I²S TX.
The key algorithm: track observed download rate × content_length to estimate “how much download is left,” and only call audio_service_pcm_stream_start once the pre-buffer covers prebuf_audio_ms ≥ remaining_download_ms × 0.7. No matter how slow the network is, the ring never under-runs.
Reading digits aloud
The TTS model regularly mangled numbers: “38640” → “34680,” “532” → “332,” “024” → “zero hundred two ten four.” TTS instructions can’t force a reading style.
The fix is full text-layer preprocessing: convert 1-99 to natural Chinese numerals (“11” → “十一”), 3+ digits per-digit (“2026” → “二零二六”), decimal point → “点”, leading-zero pairs preserved (“01” → “零一”, fixing the “12:01” → “12:1” zero-drop bug), ℃/° → “度”, % → “百分”.
Function-calling side-effect timing
First implementation of set_timer(seconds): the user says “beep in 5 seconds” — and hears the beep before GPT finishes saying “sure, timer set.”
Cause: tool execution is synchronous, so esp_timer_start_once(5_s) fires immediately. But there’s still a GPT round 2 (5-10 s) plus TTS download + playback (15 s) ahead — the timer fires before TTS even starts.
The fix: the tool doesn’t start esp_timer directly. It stashes seconds in a static variable, and cloud_pipeline_task calls cloud_pipeline_fire_deferred_timer() only after TTS playback finishes. The variable resets at the start of every turn so a failed timer from a previous turn can’t leak into the next.
Limitations
- The on-device AI is still a dummy / skeleton. The “AI 1MS” line on the HUD only exercises the local inference scheduling framework — no real model attached. Real on-device AI is still TODO before the competition.
- Fully cloud-dependent for LLM. No internet, half the features die. OpenAI / Groq have real-world issues — slow responses (GPT POST 30+ s), region instability, quota limits.
- Round-trip 30-40 s isn’t fast. The bottlenecks are ASR upload and TTS download. Next experiment: Opus-encoded audio upload (WAV 100 KB → 10-15 KB) and GPT-4o SSE streaming.
- Physical UART layer still drops 1.3% downlink. Considering bare DuPont wires with no flow control that’s not bad — but stability comes from retransmission, not from the physical layer.
- Only two cloud APIs are wired up (OpenAI + Open-Meteo). Demoing anything else means more integration.

The repo’s 00_docs/DEVELOPMENT_JOURNEY.md is the full granular log — commit traces, error codes, speedup ratios for every problem.